고정 헤더 영역
상세 컨텐츠
본문
반응형
정보수집 : 모의해킹의 대상을 정하고 나면 가장 처음 수행하는 단계.
수집할 정보
-
웹 애플리케이션을 서비스하기 위한 호스트 환경(운영체제, 웹 서버, 웹 프레임워크)에 대한 정보
-
웹 애플리케이션 자체에 대한 정보
방법
1. 배너를 통한 정보 수집
-
응답 메시지의 서버 헤더를 살펴본다.(Windows : F12, Mac : Ctrl+Shift+K)
-
서버의 응답을 통해 정보를 수집하는 방법을 배너 그래핑(Banner Grabbing)이라고 한다.

-
서버 헤더를 통해, 아파치 웹 서버 버전 정보, 운영체제, PHP버전 정보, Open SSL 정보 등 각종 정보를 쉽게 알 수 있다.
※ 버프 스위트의 히스토리 기능을 통해서도 확인할 수 있다.
2. 기본 설치 파일을 통한 시스템 정보 수집
-
종종 웹 애플리케이션을 운영하기 위한 웹 서버와 웹 프레임워크, 기타 구성 요소들을 설치할 때 기본으로 설치되는 파일로 인해 호스트 환경에 대한 정보가 노출된다.

3. 웹 취약점 스캐닝
-
자동화된 프로그램을 이용하여 웹 사이트의 여러 가지 정보를 수집하고 이 정보들을 바탕으로 어떤 취약점이 있는지 알아내는 과정이다.
-
많은 트래픽을 유발할 수 있으므로 주의하여 실행하도록 한다.

-
이와 같은 출력된 결과를 통해 서버 헤더, PHP, 아파치, mod_ssl의 버전, 보안 관련 헤더 설정 여부, 허용된 메소드 목록 정보, 디렉터리 인덱싱, phpMyadmin(웹으로 DB설정을 가능하게 해주는 프로그램), 디렉터리 발견 등 취약점을 발견할 수 있다.
4. 디렉터리 인덱싱
-
웹 서버의 잘못된 설정으로 웹 서버 디렉터리 파일들이 노출되는 취약점이다.
-
사용자가 웹 브라우저의 주소를 디렉터리 경로를 요청할 때, 지정된 파일들이 모두 디렉터리에 존재하지 않으면 해당 디렉터리의 모든 파일 목록이 최종적으로 출력된다.

-
위와 같이 img파일이 노출되는 것은 크게 문제가 안되지만, document 디렉터리, password, 백업파일 등이 노출되면 각종 문서 파일들이 노출되어 문제가 발생한다.(민감한 데이터 노출)
5. 웹 애플리케이션 매핑
-
웹 애플리케이션 지도를 그리듯, 웹 애플리케이션의 메뉴와 링크를 따라가면서 어떤 URL과 파라미터들이 전송되는지 웹 애플리케이션의 구조를 파악하는 과정이다.
-
이를 통해 공격지점을 찾는다.
5-1. 수동 매핑
-
직접 웹 애플리케이션에 접속하여 각 메뉴를 확인하는 과정이다.
-
버프 스위트의 사이트 맵 기능을 활용할 수 있다.

5-2. 크롤링(crawling)
-
크롤링을 이용하면 웹 애플리케이션 매핑 과정을 자동으로 수행한다.(크롤러로 수행)
-
동작
-
크롤러가 처음 지정된 URL로 요청한다. 이 URL은 크롤러를 처음으로 시작할 때 사용자가 지정하게 되는데, 웹 로봇과 같은 크롤러는 robots.txt라는 파일을 읽고 크롤링을 시작한다.
-
처음 요청에 의해 전송받은 응답 메시지를 분석하고, 응답에 포함된 링크를 각각 추가로 요청한다.
-
링크 요청에 의해 전송받은 응답 메시지를 다시 분석하고, 링크가 다시 포함되어 있으면 또다시 해당 링크를 추가 요청한다.
-
더 이상 링크를 찾을 수 없거나 404나 500 등과 같은 에러 메시지가 응답될 때까지 이 과정을 반복한다.
-
-
버프 스위트의 스파이더 기능으로 실행 가능하다.
-
수동 매핑으로 사이트의 구조를 파악한 후에 스파이더 기능을 추가로 실행하는 것이 정확하고 효율적이다.
5-3. DirBuster
-
URL 목록 파일을 사용하여 각 URL을 자동으로 입력해보는 방식으로 웹 애플리케이션의 구조를 파악한다.
-
링크를 따라가는 스파이더 기능과 달리, 숨겨진 페이지를 찾을 수 있다.
- Dirbuster로 찾은 URL을 직접 접속해 보면서 수동 매핑과 크롤링을 추가로 연계해 나갈 수 있다.

5-4.robots.txt
-
웹 사이트의 운영자는 robots.txt 파일을 웹 사이트의 가장 상위 디렉터리에 위치시켜, 웹 로봇에 해당 웹 사이트의 정보 수집을 허용 허거나 불허하는 명령을 내릴 수 있다.
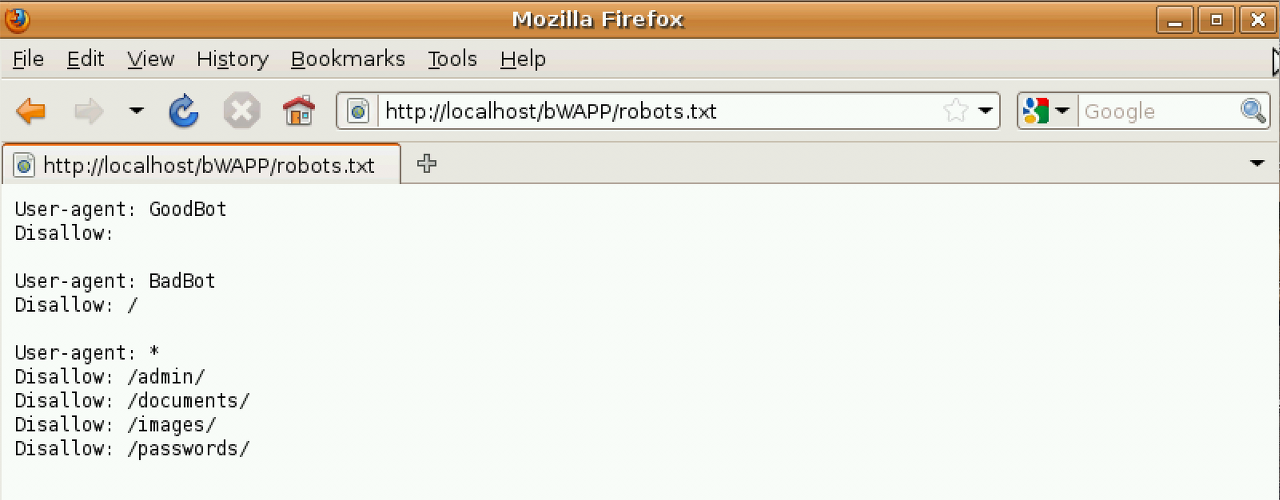
-
웹 사이트의 운영자는 User-agent 키워드를 이용하여 지정된 User-agent 요청 헤더를 전송하는 특정 로봇에게 명령을 내릴 수 있다.
-
위의 해석
-
GoodBot 로봇의 수집을 불허하지 않는다.
-
BadBot 로봇을 대상으로는 모든 페이지에 대한 수집을 불허한다.
-
/admin/,/documents/, /images/, /password/ 디렉터리에 대한 수집은 모든 로봇을 불허한다.
-
-
악의적인 로봇은 이 내용을 무시하고 Disallow 키워드로 차단한 내용을 정보 수집에 오히려 활용한다.

-
위의 화면과 같이 악의적인 목적으로 접근할 수 있다.
정보 수집 대응 방법
-
불필요한 정보 노출 삭제 : 헤더 삭제, 설정 파일 노출 방지, 백업 파일 노출 방지
-
스캐너/크롤러 차단 : 로깅과 모니터링 활용(nikto, sqlmap, 침입 탐지 시스템(IDS/IPS)) -> IP
-
디렉터리 인덱싱 설정 제거 : 웹 서버의 설정을 변경하여 대응, 아파치의 경우 아파치 설정 파일의 Indexes 옵션을 제거하여 디렉터리 인덱싱으로부터 보호할 수 있다.

-
위의 옵션을 제거함으로써 디렉터리 인덱싱이 되지 않도록 설정할 수 있다.
-
IIS 서버의 경우에도 '디렉터리 검색' 옵션을 비활성화함으로써 디렉터리 인덱싱이 되지 않도록 설정할 수 있다.
-
급히 디렉터리 인덱싱을 차단하고자 한다면 해당 디렉터리에 임의의 index.html 파일을 생성해주는 방법도 있다.
위 글은 '화이트 해커를 위한 웹 해킹의 기술 최봉환 저'를 공부하며 작성한 글입니다.
728x90
'화이트 해커를 위한 웹 해킹의 기술' 카테고리의 다른 글
| Step6. 크로스 사이트 요청 변조(CSRF) 공격 (0) | 2021.02.26 |
|---|---|
| Step5. 크로스 사이트 스크립팅 공격 (0) | 2021.02.25 |
| Step4. 커멘드 인젝션 공격 (0) | 2021.02.24 |
| Step3. SQL인젝션 공격 (0) | 2021.02.23 |
| Step2. 취약한 인증 공격 (0) | 2021.02.21 |





댓글 영역